
„Künstliche Intelligenz“, „Deep learning“ oder „Machine learning“ werden aktuell als Allheilmittel für viele dringende Problem diskutiert. Sei es nun der Klimawandel, soziale Umwälzungen wie beispielsweise die Alterung der westlichen Gesellschaften oder die „Coronakrise“.
Supercomputer in aller Welt „rechnen“ an einer Lösung. Mehrere tausend Substanzen werden auf ihre Eignung zur Bekämpfung von Covid_19 analysiert. Dabei wird die Proteinfaltung mit der Oberfläche des Virus verglichen und die künstlichen Intelligenzen errechnet, wie hoch die Wahrscheinlichkeit ist, dass eine spezifische Substanz durch ihre chemische Struktur das Eindringen des Virus in eine menschliche Zelle verhindern kann.
Die KI trifft dann eine negative Vorauswahl. Es werden nämlich die Substanzen herausgefiltert, die mit großer Wahrscheinlichkeit nicht (sic!) funktionieren würden.
Übrig bleiben dann hoffentlich alle diejenigen Substanzen, die zumindest eine kleine Chance bieten, von medizinischem Nutzen zu sein. Auf diese kann sich dann die weitere Forschung konzentrieren.
Qualität von KI beschreiben
Kann man die Leistungsfähigkeit der beteiligten Maschinen bewerten? Gibt es Messzahlen, die erkennen lassen, ob ein KI_Modell gute Ergebnisse produziert? Oder handelt es sich zwangsläufig um ein geschlossenes System, eine Blackbox?
Zunächst einmal geht es bei diesen Beispielen um Sortieraufgaben, um Klassifikationen. Es handelt sich also bei den im folgenden betrachteten Systemen um Klassifikatoren.
Und jetzt kommen die Begriffe „Accuracy“, „Recall“, „Precision“ sowie „F1“ ins Spiel. Mit ihrer Hilfe kann man bewerten, ob ein Klassifikator für seinen Einsatzzweck genau genug ist oder nicht.
Allgemein wird oft „Accuracy“ also „Genauigkeit“ als grundlegender Wert für die Treffsicherheit genannt. Jedoch erweist sich dieser Wert in vielen Anwendungsszenarien als trügerisch und manchmal als völlig sinnfrei.
Schauen wir uns erst einmal die Grundlagen an.
Die Basis: Die Confusion Matrix
Die sogenannte „Confusion Matrix“ stellt die Basis für einen KI-Benchmark dar.
Sie ist eine zweidimensionale Anordnung von Zahlenwerten. Sie kennt nur „richtig“ und „falsch“ als Klassifikation.
Wichtig ist dabei, dass alle Ergebnisse verifiziert sind, bevor sie zum Einsatz kommt. Hat man also eine KI-Anwendung z. B. auf das Erkennen von Katzenbildern trainiert, wird diese Tabelle mit einer Anzahl von Datensätzen (Bildern) gefüttert, von denen vorab klar oder zumindest zweifelsfrei festgestellt ist, wieviele Bilder wirklich Katzen enthalten und wieviele nicht und in welchem Bild diese Katzen dargestellt sind und in welchen Bildern nicht.
Die Anwendung selbst ist, da sie Datensätze nach „mit Katze“ und „ohne Katze“ klassifiziert, ein sogenannter „classifier“.
Nachdem die Anwendung nun die (bekannten) Bilder klassifiziert hat, erstellt man mit den gewonnenen Daten die Confusion Matrix.
Negative (Klassifizierung), KI stellt fest, dass ein Bild keine Katze enthält |
Positive (Klassifizierung), KI stellt fest, dass das Bild eine Katze enthält |
|
|---|---|---|
|
Negativ (Real), Bild enthält keine Katze |
richtig negativ |
falsch positiv |
|
Positiv (Real), Bild enthält tatsächlich eine Katze |
falsch negativ |
richtig positiv |
In diese Matrix werden nun die gewonnenen Daten eingetragen:
| Negativ (Klassifizierung) | Positiv (Klassifizierung) | |
|---|---|---|
|
Negativ (Real) |
113 („keine Katze“), Bild enthält keine Katze und KI klassifiziert auch so. |
31 („falsche“ Katzen), fälschlicherweise als positiv („mit Katze“) klassifizierte Bilder |
|
Positiv (Real) |
22 ( die Katze wurde nicht erkannt) fälschlicherweise als negativ („ohne Katze“) klassifizierte Bilder | 34 („mit Katze“) Bild enthält Katze und KI klassifiziert auch so. |
Mehrere Classifier
Eine KI-Anwendung besteht allerdings oft aus mehreren „Classifiern“. Diese arbeiten hintereinander. In unserem Katzenbeispiel lässt man einen zweiten „Classifier“ (C2) die Ergebnisse des ersten (C1) bearbeiten, um Bilder mit „schwarzen Katzen“ herauszufiltern.
Dabei bearbeitet der zweite Classifier alle 65 vom ersten als „mit Katze“ klassifizierten Datensätze. Die falsch als „mit Katze“ klassifizierten Bilder und die richtig als Katzen erkannten. Die falsch als „mit Katze“ klassifizierten 31 Bilder sind zu viel und die 22 falsch negativ als „ohne Katze “ klassifizierten Bilder fehlen. Der zweite Classifier in unserem System arbeitet trotzdem damit weiter.
Der nachgeschaltete Classifier versucht nun, aus den ihm übergebenen Datensätzen mit 65 echten und vermeintlichen Katzendarstellungen, diejenigen mit einer schwarzen Katze zu finden. Das Ergebnis könnte so aussehen:
| Negativ (Klassifizierung durch C2) | Positiv (Klassifizierung durch C2 ) | |
|---|---|---|
|
Keine Katze (aber falsch Positiv Einschätzung C1) |
14 (keine schwarze Katze) |
7 („falsche“ schwarze Katzen) |
|
Katze (korrekte Einschätzung C1) |
4 (schwarze Katze, wurde aber nicht erkannt) |
30 (schwarze Katze) |
Wie man nun sieht, gibt es folgendes Problem: der erste Classifier hat relativ viele falsche Annahmen getroffen und diese an den zweiten Classifier weitergereicht. Der zweite Classifier muss nun mit fehlerhaften Daten arbeiten.
Besonders wichtig ist bei diesem Beispiel die Leistung des ersten Classifiers, da der zweite mit den Daten des ersten arbeitet. Man kann sich leicht vorstellen, wie bei einer steigenden Anzahl von hintereinander arbeitenden Classifiern Fehler innerhalb der Gesamtanwendung kaskadieren und sich gegebenenfalls auch potenzieren.

Die Messgrößen
Mit dem Beispiel der Katzenbilder wäre das Ergebnis ärgerlich aber kaum gefährlich. In einer Verkehrszeichenerkennung eines PKW allerdings wäre so eine Fehlerrate mehr als unerwünscht. Einen Ast als Schild zu identifizieren und dieses Schild im Nachgang als Stoppschild zu klassifizieren wäre auf einer Autobahn unter Umständen tödlich, wenn der PKW eine Notbremsung einleitet.
Daher muss es Möglichkeiten geben, eine KI für ihr jeweiliges Anwendungsfeld zu bewerten. Dazu dienen im Wesentlichen die folgenden etablierten Kennwerte:
- „Accuracy“,
- „Precision“,
- „Recall“ sowie
- F1.
Accuracy
Für jede „Confusion Matrix“ kann man nach folgender Formel einen Wert errechnen für die „Genauigkeit“:

Umso höher der Wert (Maximum ist 1), umso genauer, akkurater ist unser Classifier.
In unserem Beispiel aus Table 2. Fig. 2 gilt dies für:
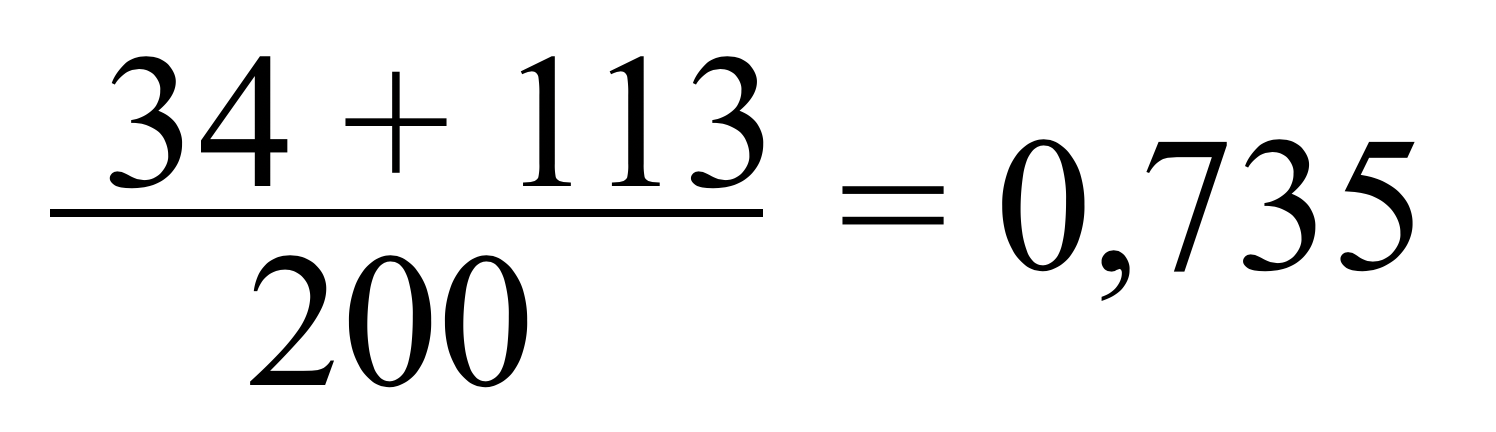
Oder etwas anders ausgedrückt: unsere KI hat eine Trefferquote von 73,5%., weil 73,5 % der Fälle richtig klassifiziert worden sind. Das ist nicht besonders genau ist und lässt noch Luft nach oben. Man sieht schon als erster Classifier in einer Reihe ist diese Lösung nicht geeignet.
Wir können, wenn das nicht reicht, den Classifier verbessern, in dem wir ihn mit noch mehr Bildern trainieren, die Katzen und andere Tiere enthalten:
Die neue Confusion Matrix sieht nun so aus:
| Negativ (Vorhersage) | Positiv (Vorhersage) | |
|---|---|---|
|
Negativ (Real) |
137 (keine Katze) |
0 („falsche“ Katze) |
|
Positiv (Real) |
10 (hat Katze, wurde aber nicht erkannt) |
53 (hat Katze) |
Daraus ergibt sich folgender Accuracy-Wert:
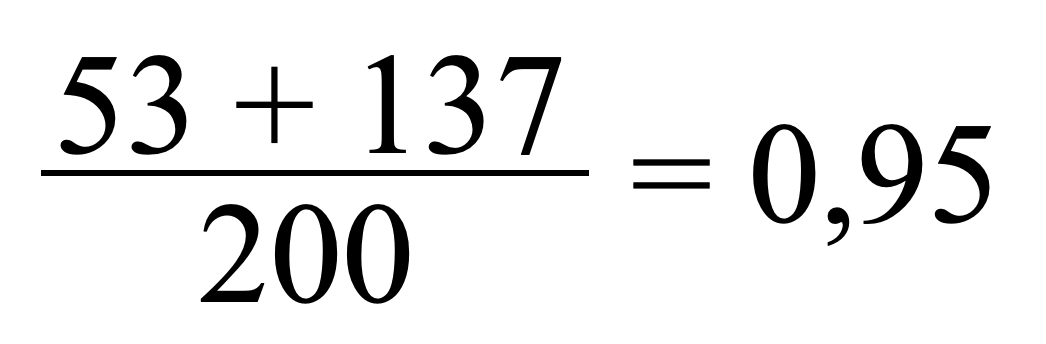
Der Classifier hat jetzt mit 95% Trefferquote eine wesentlich höhere Genauigkeit bei der Vorhersage.
Je nach Anwendungsfall wäre diese Quote schon brauchbar. Viele Menschen wären vermutlich froh, wenn ihr Spamfilter eine solche Trefferquote erreichen würde. Für eine Verkehrszeichenerkennung wäre diese Quote aber noch immer zu schlecht. Wir hätten zwar keine falschen Positiveinordnungen (ein Verkehrsschild, welches keines ist) mehr, aber immer noch einige falsche Negativklassifizierungen. Real vorhandene Verkehrsschilder würden übersehen. Und somit nicht an den zweite Klassiker weitergegeben, der z. B. auf der Bassis des Ersten die genaue Bedeutung der Schilder feststellen soll.
Bei Anwendungen, für die die lückenlose Erfassung von etwas vorhandenem wichtig ist, sollte man daher Accuracy nicht nutzen.
Hier kommen nun „Precision“ und „Recall“ ins Spiel.
Precision
Precision klingt besonders gut. Daher prüfen wir im nächsten Schritt: Kann bei diesem Beispiel Precision helfen?
Die Formel sieht wie folgt aus:

Diese Gleichung können wir nun mit Zahlenwerten füllen. Als Beispiel dienen wieder die Werte aus Fig. 6:
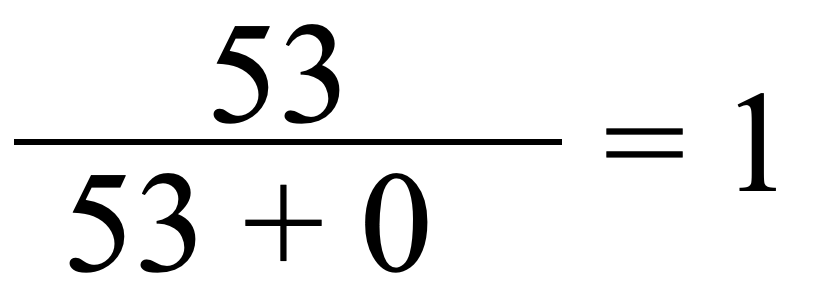

Nach dieser Formel ist die Präzision der KI 100%. Precision ist also für die Bewertung der gar nicht erkannten vorhandenen Schilder oder Katzen auch nicht geeignet.
Im Gegenteil. Sie gibt uns eine Hundertprozentige Erkennung an. Das liegt daran, dass die Werte, die unter Precision errechnet werden, nur die richtig und falsch Positiv klassifizierten berücksichtigen und eben nicht die übersehenen, also die falsch negativ klassifizierten.
Precision kann also nur dazu dienen, die Genauigkeit der Vorhersage hinsichtlich der falsch positiven Klassifizierungen zu bewerten. Und auch nur dazu kann sie nützlich sein.
 |
Precision erlaubt eine Einordnung der Genauigkeit in Hinblick auf falsch positive Ergebnisse eines Classifiers. Falsch negative Ergebnisse bleiben außen vor. |
Recall
Dann müsste uns aber in unserem Beispiel der Gegenspieler von Precision, der Wert für Recall als „Maßeinheit“ für die Betrachtung der Qualität helfen!

Schauen wir uns noch einmal die Confusion Matrix aus Fig. 6 an. Mit der obigen Gleichung ergibt sich:
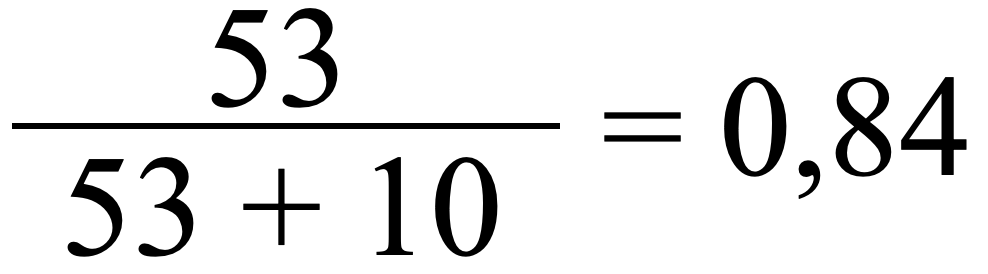
Der Recall-Wert liegt also bei 84% Genauigkeit hinsichtlich der falsch negativ Klassifizierten Daten. Das ist viel niedriger als der Wert für Precision, der ja bei „1“, also hundert Prozent lag und auch deutlich niedriger, als der Wert für Accuracy.

Der mittels der Recall-Formel errechnete Wert stellt die Genauigkeit im Hinblick auf falsche Negativklassifizierungen dar.
Je nach Anwendungsfall ist es wichtiger, falsch negative Voraussagen zu reduzieren als falsch positive Voraussagen. Bei der Kreditvergabe entgehen der Bank wegen der Ablehnung eines Kunden wegen einer falsch negativen Klassifikation die anfallenden Zinsen eines Kredites.
Kommt es jedoch aufgrund von falsch positiven Klassifikationen zu zu vielen Kreditverträgen mit nicht wirklich kreditwürdigen Kunden, drohen Zahlungsausfälle, die die Bank gefährden könnten.
(Wir klammern für das Beispiel den Imageschaden einmal aus, der z. B. in einem Fall entstehen kann, wenn einer einflussreichen Persönlichkeit ein Kredit abgelehnt wurde.)
|
Der Recall-Score erlaubt die Einordnung der Ergebnisse in Hinblick auf die Rate von falsch negativen Klassifikationen eines Classifiers. |
In diesem Sinne kann man Precision als das Gegenteil von Recall sehen. Je nach Nutzungsszenario ist eine falsch negative Klassifikation weniger teuer als eine falsch positive oder umgekehrt.
Man kann also mit Precision die Genauigkeit der Vorhersagen hinsichtlich einer positiven Klassifikation gut beschreiben. Mit Recall kann man dies in Hinblick auf negative Klassifikation ebenfalls gut.
Daraus resultiert natürlich die Frage, ob man diese beiden Werte besser miteinander kombinieren kann als in der Quantifizierung des Wertes für Accuracy, die wir eingangs betrachtet haben.
Das würde man immer brauchen, wenn eine asymmetrische Betrachtung der Qualität nicht reicht, sondern wenn man einen aussagekräftigen Gesamtscore benötigt. Die Antwort ist: Man kann!
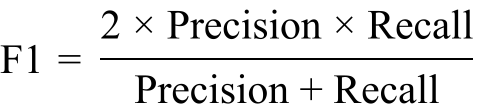
F1
Der als „F1“ bezeichnete Wert ist der Durchschnitt aus „Recall“ und „Precision“. Er ermöglicht es, die Gesamtgenauigkeit der Vorhersagen eines Classifiers zu beschreiben.
tragen wir hier die Werte zu unserer letzten Confusion Matrix aus Fig 6 ein:
Fig. 13
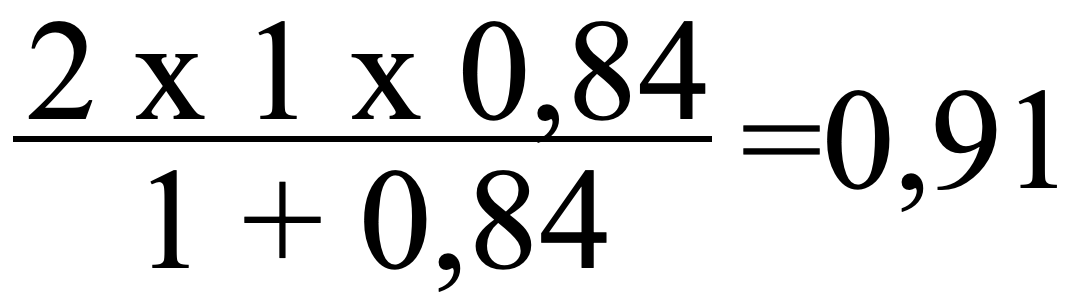
Man sieht: ein Mittelwert zwischen Recall und Precision macht durchaus Sinn, um die allgemeine Genauigkeit einer Anwendung oder eines Classifiers zu bewerten.
Der F1-Wert liegt nun mit 0.91 zwischen Recall und Precision. Die allgemeine Genauigkeit unseres Classifiers liegt nun wesentlich höher als der Recallwert, vermittelt aber nicht die falsche Sicherheit aus dem Wert mit dem irreführenden Namen „Precision“. Wir können damit die Qualität der Rate an richtig positiven und richtig negativen Klassifikationen insgesamt beurteilen.
|
Der F1-Score erlaubt eine Einschätzung bezüglich der allgemeinen Genauigkeit eines Classifiers. |
Ausblick
Was können wir daraus lernen?
Nun, zum einen:

Auch Maschinen machen Fehler und je nachdem wie die Datenlage war und ist, wie das System trainiert wurde und welche Schlüsse für Optimierungen aus Benchmarks gezogen wurden, kann die Fehlerrate enorm sein. Es gibt aber Kennzahlen, mit denen wir uns als Nutzer über die Fehlerrate und die möglichen Fehlerrichtungen informieren können.
Es ist eben nicht so, wie der Umgang mit unserem Computer im Alltag. Wir vertrauen darauf, dass Excel richtig rechnet, sogar statistische Tests durchführt und dass die Textverarbeitung unsere Texte richtig wiedergibt. Aber schon da bemerken wir, dass manches „korrigierte“ Wort von der im Hintergrund automatisch mitlaufenden Rechtschreibkorrektur verschlimmbessert wird, falsch wird. Eben habe ich „Klassifikator“ eingetippt und musste zweimal der Korrektur widerstehen, die „Klassifikation“ daraus machen wollte.
Und bei komplexen KI Systemen wird es noch viel viel komplexer, oder komplizierter. Da sollte man immer hinterfragen, welche „technischen Daten“ wir dazu erfahren können.
Die oben beschriebenen Kennzahlen sollten bei Klassifikationssystemen immer hinterfragt werden.
Betrachtet man z. B. Gesichtserkennungssysteme, deren Einsatz von Politik und Wirtschaft teilweise vehement gefordert werden, so stellt sich die Frage, was ein System mit 99% Erkennungsrate letztlich bedeuten würde. Und welche Zahl ist damit genau gemeint? Accuracy? Recall? Was heißt erkennen? Die Identität feststellen oder auch in eine Gefahrengruppe einsortieren?
Würde man ein solches System auf dem Frankfurter Flughafen nutzen (70,5 Millionen Passagiere im Jahr Fraport), so hätte man rund 0,7 Millionen fehlerhafte Ergebnisse. Das wären fast 2.000 pro Tag. Würden diese Fehler in Fehlalarmen resultieren oder in übersehenen Gefährdern? Da muss man genauer hinsehen: Accuracy, Recall, Precision oder F1?
Auch klar ist, dass es einen Unterschied gibt ob ich mit meinem Gesicht mein iPhone entsperren will (Nur ein Classifier. Bin ich es oder nicht?) oder ob ich spezifische Personen aus einem riesigen Pool von Personen filtern möchte.
Was man also sicherlich überdenken muss, ist die vorschnelle Einführung von KI-Anwendungen in einer Vielzahl von Lebensbereichen und in der Arbeitswelt. Die Potentiale sind in jedem Fall gegeben und es ist letztlich nicht mehr die Frage ob sondern wann KI-Anwendungen einen Lebensbereich erobern. Bevor es aber soweit ist, müssen Recall und Precision stimmen!
Zum Einsatz von KI im Personalbereich hat mein Kollege Harald Ackerschott in einem Artikel auf LinkedIn schon letztes Jahr die fehlende Transparenz reklamiert.
Quellen
Golem.de:
Heise:
Deutschlandfunk
NIST
Fraunhofer Gesellschaft
Wikipedia
Pathmind
Anmerkung der Publisher dieser Seite:
Praktische Lösungen finden Sie hier:
Darüber hinaus gibt es laufend weitere Vertiefungen und Themen rund um Personalentscheidungen und die dazu gehörenden Eignungsbeurteilungen hier auf eignungsdiagnostik.info.
Wir möchten, dass Sie als Unternehmerin oder Unternehmer bzw. als Führungskraft, die Möglichkeit haben, ihren Erfolg durch noch bessere Personalentscheidungen weiter zu steigern. Dafür haben wir unsere in vielfältigen, auch internationalen Einsätzen gewonnene langjährige Erfahrung und nützliche Erkenntnisse aus der Wissenschaft in die Konstruktion unser Online Assessment Systems einfließen lassen:
Sprechen Sie uns gern direkt dazu an. Schicken Sie mir Direktnachrichten auch gern direkt über
Folgen sie gern auch unserem Podcast:
https://link.chtbl.com/zUjaDMl7
Wenn er Ihnen gefällt, freuen wir uns über Ihre fünf Sterne Bewertung.
[…] kann) ergänzt die Eignungsdiagnostik nach DIN 33430 und berücksichtigt dabei auch den Einsatz von künstlicher Intelligenz (KI) in […]